BigQuery
- 데이터 저장 및 분석용 Data Warehouse
- 여러 프로젝트에서 만들어지는 로그들을 한 곳으로 모아 보기 쉽게 쿼리할 수 있음
- 다양한 쿼리를 통해 데이터를 분석하는 것을 도와주는 서비스
ex) A 프로젝트의 logs router에서 sink를 생성할 때 B 프로젝트의 빅쿼리를 destination으로 설정해주면,
A 프로젝트의 로그가 B 프로젝트의 빅쿼리에 쌓이게 됨
구성
Dremel(Compute) : SQL 쿼리 수행
Colossus(Storage) : 데이터의 저장, 실시간 처리가 가능한 분산 파일 시스템
Jupitoer(Network) : Compute와 Storage 사이의 통신 담당
Borg(Orchestration) : 분산 노드들의 조율 및 운영
특징
- No-Key, No-Index (Full Scan Only)
- No Update, Delete ROW
- Eventual Consistency
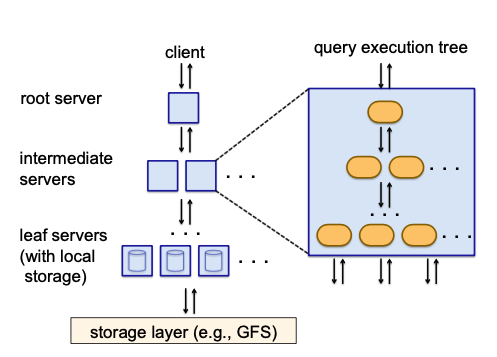
Tree Architecture
- 쿼리를 root server, intermediate server에서 차례로 잘개 쪼개서 leaf server로 보냄 -> 쿼리 결과를 역순으로 취합
- 병렬 연산 수행 가능 -> Big Query가 빠른 이유
Query Dispatcher
- 요청 받은 여러 쿼리들의 우선 순위 설정, Scheduling 및 Load balancing 수행
- 쿼리를 slot이라는 단위로 병렬 처리
- fault tolerence 수행 (특정 노드의 쿼리 수행 속도가 느릴 경우 다른 노드에 일임)
In Memory Query Execution
- Shuffling을 통한 데이터 교환 작업
- 메모리 단에서 모든 연산과 데이터 통신
- MapReduce와 달리 처리가 끝난 데이터는 Shuffling 과정이 끝나기 전 다음 처리 과정으로 넘어감
출처
'IT > Cloud' 카테고리의 다른 글
| [GCP] Instance Group (0) | 2022.02.23 |
|---|---|
| 3 Tier Architecture가 필요한 이유 (0) | 2022.02.21 |
| [GCP] VPC Service Control (0) | 2022.02.16 |
| CI/CD가 필요한 이유 (0) | 2022.02.14 |
| VM vs Container (0) | 2021.09.18 |


댓글